 Linux常用命令
Linux常用命令
# Linux常用命令
# vim
vim filename # 可直接新建文件,打开文件后默认进入命令模式。
vim +n filename # 打开文件并跳转到指定行, n代表数字
vim -R filename # 以只读模式打开文件
2
3
vim有三种主要模式——普通模式(按Esc进入)、插入模式(按i或a)、命令模式(按: 进入命令模式)
# 插入模式
- i: 光标前插入
- I: 行首插入
- a: 光标后插入
- A: 行尾插入
- o: 光标下方新建一行并进入插入模式
- O: 光标上方新建一行并进入插入模式
# 普通模式
# 光标移动
- G: 移动到文件末尾(可以与o一起使用,快速在文件末尾插入)
- gg: 移动到文件开头
- $: 移动到行尾
- 0: 移动到行首
- ^: 移动到行首第一个非空字符
- :number: 跳转到指定行
# 文本操作
- dd: 删除当前行
- ndd : 删除从光标开始的n行
- u: 撤销操作
- yy: 复制当前行
- p: 粘贴到光标后
- P: 粘贴到光标前
- nyy: 复制从光标开始的n行
- u: 撤销上一步操作
- . : 重复上一条命令
可视模式(按 v 或 V 进入)用于选择文本块,操作后会自动返回普通模式。
按y复制、按d删除(相当于剪切)、按p粘贴
# 操作和替换
- /content: 向下查找
- ?content:向上查找
- :%s/old/new/g: 全局替换old为new
- n,m s/old/new/g: n到m的old替换为new
# 命令模式
- :w :保存文件
- :q : 退出vim
- :wq :保存并退出
- :q! :强制退出, 不保存
- :set nu : 显示行号
- :set nonu : 取消行号显示
# du
如果你想查看一个目录下的内容大小,如果使用
ls -lh
你会发现,如下图的情况(文件显示大小了,而目录则没有)
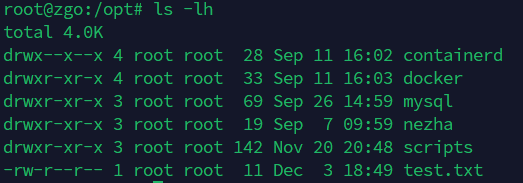
这个时候就要请出du了
| 参数 | 含义 |
|---|---|
| s | 只显示总大小 |
| h | 以人类可读的格式显示(KB、MB) |
| a | 显示目录中文件和所有子目录的大小 |
当然还有很多参数,这里只展示本人常用的(肯定不是我懒得整理.............)
du -sh *
结果如下图:
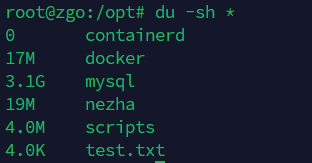
当然可以查看特定目录的大小如下
du -sh /opt/mysql

# tar
打包一个目录(以下命令是打包/opt目录下所有内容到/opt/backup/目录下,并命名为opt_backup.tar.gz)
tar -zcvf /backup/opt_backup.tar.gz /opt
当一个目录下有不想要的文件或目录怎么办??(哈哈哈,当然是凉拌)
下面是如何凉拌的
tar -zcvf /backup/opt_backup.tar.gz --exclude=/opt/mysql --exclude="*.txt" /opt
这里有几个需要注意的点
- --exclude=/opt/mysql 排除的目录 如果你要多加个/ --exclude=/opt/mysql/ 任然会打入mysql目录下的内容(tab补全会带上/ 一定要多多注意)
- --exclude=/opt/mysql --exclude="*.txt" /opt --exclude 要在打包目录的前面
- 如果要排除的过多怎么办?
tar -zcvf /backup/opt_backup.tar.gz \
--exclude='/opt/mysql' \
--exclude='*.ibd' \
--exclude='*.txt' \
/opt
2
3
4
5
这样会造成命令过长
可以使用 --exclude-from=/backup/exclude.txt (指定你文件的位置)
vim exclude.txt
内容写要排除的内容即可,下面是个例子

tar -zcvf /backup/opt_backup.tar.gz --exclude-from=/backup/exclude.txt /opt
解压的话就常用的(就是将opt_backup.tar.gz 解压到 /opt/backup/目录下)
tar -zxvf opt_backup.tar.gz -C /opt/backup/
# rsync
| 参数 | 含义 |
|---|---|
| a | 归档模式,递归复制并保持文件属性 |
| v | 显示详细信息 |
| z | 在传输过程中压缩文件 |
| -e | 指定SSH命令及其参数 |
常用命令如下
rsync -avz -e "ssh -p 2443" /backup/opt_backup.tar.gz user@ip:/opt/
ssh -p 2443 ,-p 指定目标服务器端口
# ps
| 参数 | 含义 |
|---|---|
| e | 显示所有进程(包括其他用户的进程) |
| f | 以“完整格式”显示进程信息(包含更多字段) |
| a | 显示所有用户的进程 |
| u | 显示更多详细信息,如CPU、内存占用 |
| x | 显示没有控制终端的进程——后台进程 |
常用命令
ps -ef
ps aux
2
# nslookup
nslookup example.com
# grep
创建一个test.txt文件内容如下图
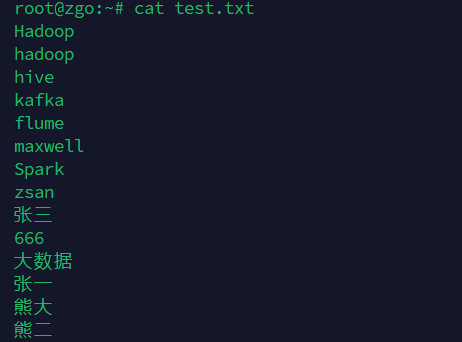
-i:忽略大小写
grep -i hadoop test.txt

-v:显示不匹配的行(反向匹配)
grep -v -i hadoop test.txt
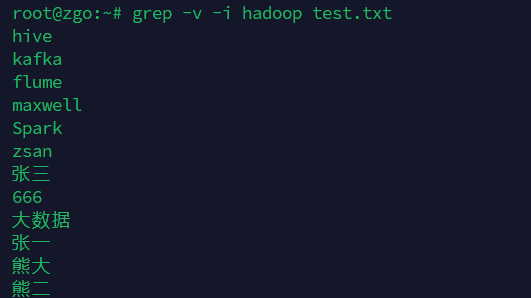
打印出包含hadoop的所有行
grep hadoop test.txt

只保留含hadoop字段的行
grep hadoop test.txt > newfile.txt

-r或-R:递归搜索指定目录下的文件*
grep -r right /opt/scripts

-l:只显示匹配模式的文件名
grep -l hadoop *.txt

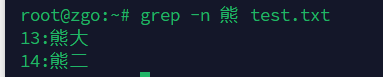
-n:显示匹配行的行号
grep -n 熊 test.txt
-c:显示匹配到的行数
grep -c 熊 test.txt

-w:只匹配完整的单词
grep -w ha test.txt
grep ha test.txt
2

-o:仅输出匹配部分,而非一整行
echo 'have a good day!' >> test.txt
grep have test.txt
grep -o have test.txt
2
3
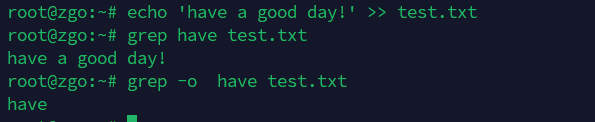
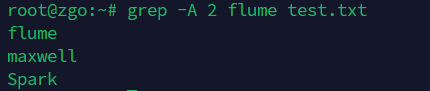
-A 数字: 显示匹配行及其后【数字】行
grep -A 2 flume test.txt
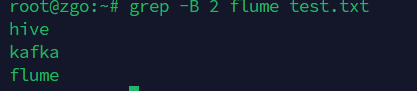
-B 数字: 显示匹配行及其前【数字】行
grep -B 2 flume test.txt
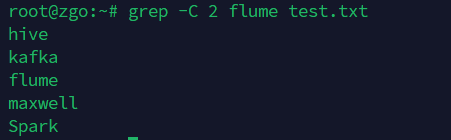
-C 数字: 显示匹配行及其前与后【数字】行
grep -C 2 flume test.txt
-E: 支持基础的正则表达式相当于 egrep
匹配包含hadoop或flume的行
grep -E "hadoop|flume" file.txt

# sed
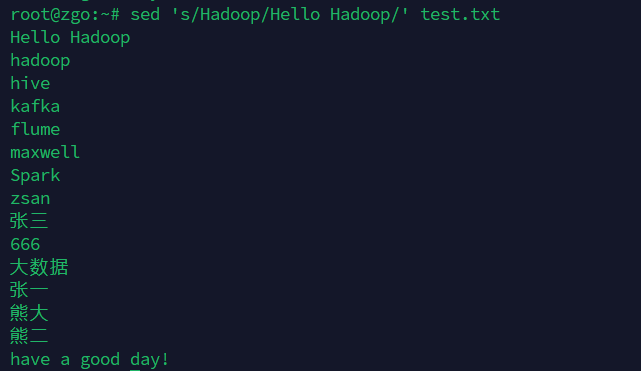
把每行中Hadoop替换成Hello Hadoop
注意这条命令不会修改test.txt的内容,只是将文件中的每一行读入缓存,执行替换输出的屏幕上。
加上-i 选项可以直接修改文件的内容。
sed只会替换每行中匹配到的第一个字符串,如果希望替换每一行中所有匹配到的字符串,需加在命令末尾上选项 g
sed 's/Hadoop/Hello Hadoop/' test.txt
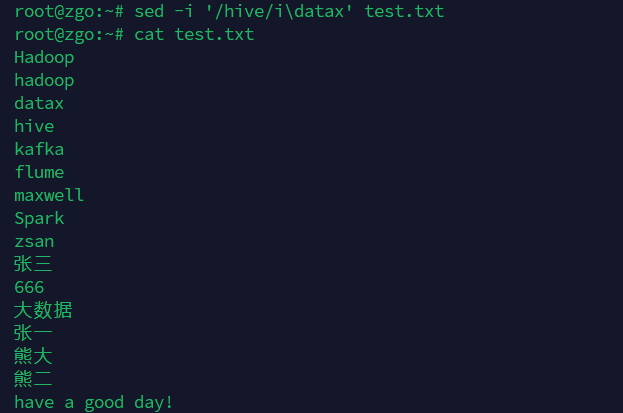
在匹配行的前面或后面添加一行(前面添加用字母i,后面添加用字母a)
sed -i '/hive/i\datax' test.txt
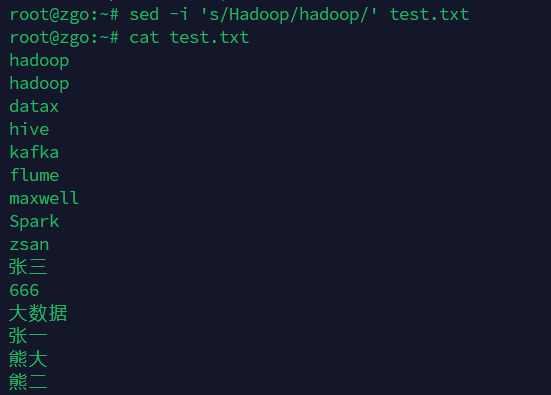
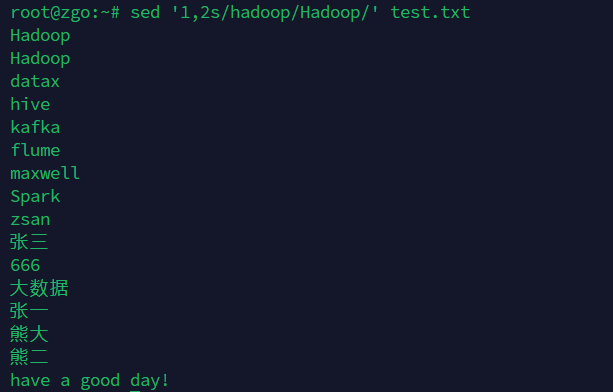
替换1,2行的hadoop为Hadoop
sed '1,2s/hadoop/Hadoop/' test.txt
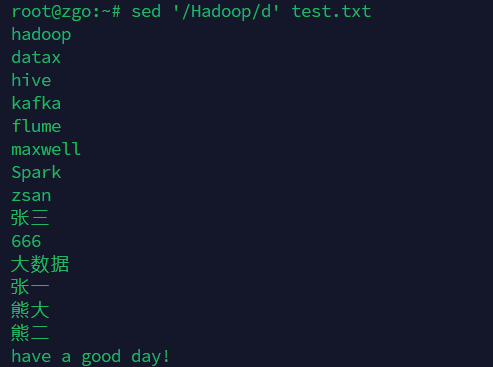
删除包含Hadoop的行
sed '/Hadoop/d' test.txt
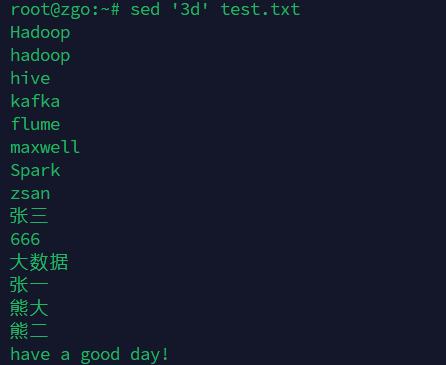
删除第五行
sed '5d' test.txt
删除第1-50行
sed '1,5d' test.txt
查看第5行到第15行
sed -n '5,15p' test.txt
# awk
准备文件内容
EmployeeID,FirstName,LastName,Department,Position,Salary,HireDate,Email,Projects
1001,John,Smith,Sales,Manager,75000,2018-03-15,john.smith@company.com,5
1002,Emily,Jones,Engineering,Developer,68000,2020-07-22,emily.jones@company.com,3
1003,Michael,Brown,HR,Specialist,52000,2019-11-30,michael.brown@company.com,7
1004,Sarah,Wilson,Sales,Associate,48000,2021-05-10,sarah.wilson@company.com,2
1005,David,Miller,Engineering,Manager,82000,2017-09-05,david.miller@company.com,9
1006,Lisa,Davis,Marketing,Analyst,55000,2022-01-18,lisa.davis@company.com,4
1007,Kevin,Zhang,Engineering,Developer,72000,2020-08-14,kevin.zhang@company.com,6
1008,Amanda,Li,Finance,Accountant,58000,2018-12-03,amanda.li@company.com,1
1009,Robert,Taylor,Sales,Associate,49000,2023-04-21,robert.taylor@company.com,0
1010,Jennifer,Moore,HR,Manager,71000,2016-06-12,jennifer.moore@company.com,8
2
3
4
5
6
7
8
9
10
11
输出文件中的每一行,并在前面加上它的行号
# 打印所有内容
awk '{print $0}' awk.txt
2
NR 是一个内置变量,表示当前处理的记录行号。默认情况下,一条记录就是一行,所以通常 NR 就表示当前的行号。
awk '{print NR, $0}' awk.txt
打印第一行
awk 'NR==1' awk.txt
打印第二到四行
awk 'NR==2,NR==4' awk.txt
打印第二行和第四行
awk 'NR==2 || NR==4' file.txt
打印Email列
# -F, 用来指定分割符号,默认是空格 '-F,'代表分隔符为,
awk -F, '{print $8}' awk.txt
2
打印“Engineering”部门的所有员工姓名
awk -F, '$4 == "Engineering" {print $2, $3}' awk.txt
打印每行列数
awk -F, '{print NF}' awk.txt
排除空行
awk 'NF > 0 {print $0}' awk.txt
# find
find [路径] [选项] [操作]
参数
| 参数 | 含义 | 代表 |
|---|---|---|
| -name | 按名字找 | "*.log" |
| -type | 按类型 | f:普通文件,d:目录 |
| -size | 按文件大小 | +10M:大于10M,-10M:小于10M |
| -mtime | 按修改时间 | +7:修改时间大于7天,-7:修改时间小于7天 |
| -atime | 按访问时间 | +7:访问时间大于7天,-7:访问时间小于7天 |
| -mmin | 按分钟 | +30:修改时间大于30分钟,-30:修改时间小于30分钟 |
查找最近7天修改过的日志文件
find /var/log -name "*.log" -mtime -7
查找并压缩旧日志文件
find /var/log -name "*.log" -mtime +30 -exec gzip {} \;
# wc
查看文件行数
wc -l filename.txt
# head
查看前10行
head -n 10 filename.txt
# tail
查看后10行
tail -n 10 filename.txt
实时查看文件
tail -f filename.txt